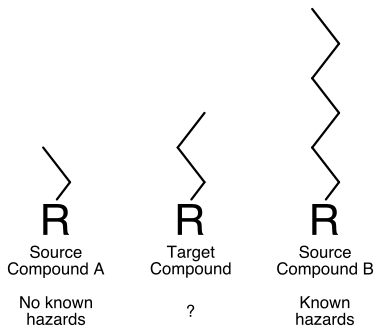
A ScitoVation Case Study A potential use case for these technologies is to augment a read-across argument for REACH registration. For illustration, consider a hypothetical class of chemicals that differ by substitution of an alkyl group (Figure- IMAGE1). Many compounds in the class have been well studied, and there is a general understanding that toxicity in a known target organ increases with chain length. A client has a target compound of interest with no toxicity database (Target Compound). The target compound has an alkyl group one carbon longer than a short chain length analog with no toxicity (Source Compound A- IMAGE 2). We offer a biological read across approach to strengthen the structure-based read across that would be the basis for the registration. The study involves selection of a suitable cell line related to the target tissue toxicity. Here, we would opt in this scenario to use two data-rich source compounds—one short chain (Source Compound A) and one long chain (Source Compound B)—in addition to the target compound. Cells would be exposed to each of the three compounds in concentration-response format. RNA would be collected and sequenced. The resulting data would be processed using our established bioinformatic pipeline, which would score the pairwise similarity between the three compounds. If the target bioactivity is similar to the short-chain source compound, this provides additional evidence for its use as a read across anchor.